
Web 前端 AI 抠图应用实践
信息时代下,图像抠图技术已经成为了一种不可或缺的技术,被广泛应用于视频直播、电商产品宣传、平面设计、背景替换等场景中。它通过将图像中的前景目标与背景软分割,实现了前景目标图像的独立提取,同时保留边缘的透明度。
传统的抠图方法通常依赖于 PS 等图像处理软件,需要人工手动进行前景目标的抠取。人工抠图可以得到高质量的结果,但也需要花费相对应的精力。面对需要大量抠图的任务场景,人工抠图的成本变得不可忽略,所以抠图自动化具有很高的应用价值。
在计算机领域,图像抠图(Image matting)是一项基本的计算机视觉问题。通过计算机计算实现的智能抠图应用,让我们仅需输入图像,算法就能自动完成前景目标的抠取。与图像分割(Image segmentation)不同的是,图像分割本质上是一种分类任务,其结果像素点透明度只能取值 0 或 1,其分割边缘为硬边缘;而图像抠图则可看为是一种回归任务,其结果是某像素点为前景的 alpha 权重概率,所以抠图结果的边缘过渡较为自然,对于毛发等边缘的细节上的保留效果要好很多。
Web 前端 AI 图像分割:Segment Anything | Meta AI

Web 前端 AI 图像抠图:Xenova/remove-background-web

随着这些年的发展,基于深度学习的图像抠图算法准确性和效率大大提升,逐渐从传统抠图算法中脱颖而出,成为抠图应用的主流技术。
图像抠图算法简介
本文的重心在于抠图算法的实际应用,这部分仅作背景简单了解
目前流行的图像抠图算法大概可以分为两种:一种是基于先验信息的方法,另一种是无需先验信息的方法。
基于先验信息的方法
在图像抠图领域中,常见的先验信息可以是 Trimap(三元图,一种将图像分为前景、背景和未知区域的标注信息)、无人的背景图像、人物姿势信息、视频临近帧等。基于先验信息的模型网络使用先验信息与图片信息共同预测 alpha。2017 年由 Adobe 提出的 Deep Image Matting 模型,就是基于 Trimap 的首个将深度学习应用于图像抠图任务的算法,在当时取得了 State-of-the-Art 的水平。
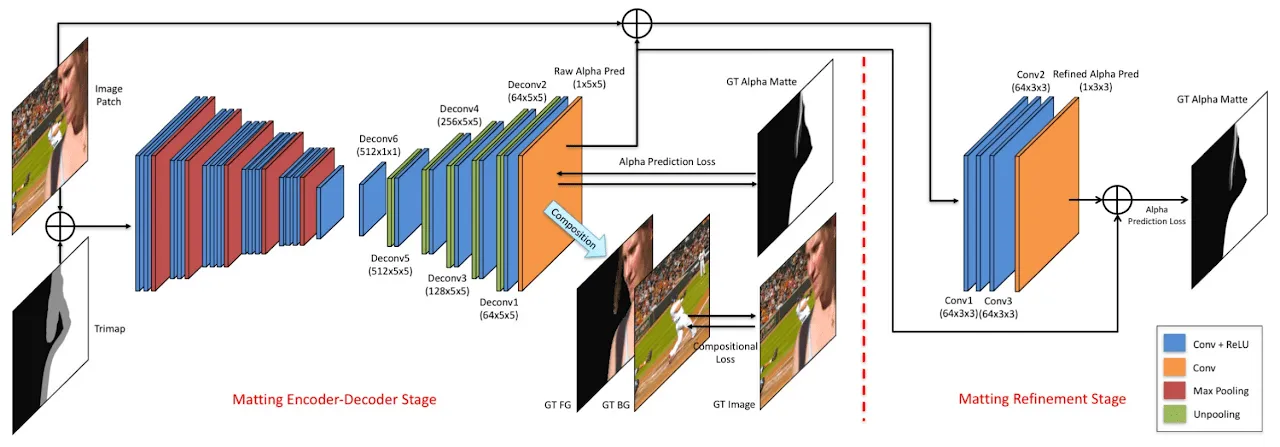
Deep Image Matting 使用了经典的 Encoder-Decoder 结构作为基本框架:预训练的 VGG-16 网络作为 Encoder 部分,对输入图像进行特征提取;Decoder 部分由多个反卷积层和 ReLU 激活函数组成,这些层用于逐步将编码后的特征图恢复到原始图像的分辨率,得到较为粗略的前景蒙版(Alpha matte)。最后 Deep Image Matting 还使用了一个小型的卷积网络,用来提升前景蒙版的精度与边缘表现。
无需先验信息的方法
另一种无需先验信息的抠图算法,网络仅根据图片本身信息对 alpha 进行预测。虽然效果往往不如第一种,但因为对于实际应用更加友好,所以是目前比较主流的研究方向。
MODNet 是香港城市大学与商汤科技于 2020 年发表的无需绿幕的实时人像抠图网络。它很好的在不使用 trimap 的情况下获得了较高的精度,同时保证了实时性,能够应用于实时视频抠图。
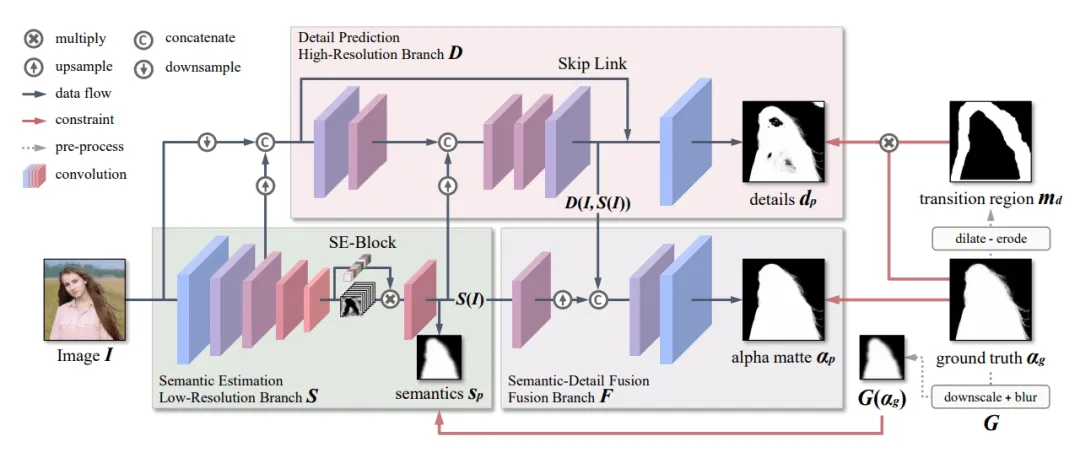
MODNet 作者认为神经网络更佳适合学习单一任务,所以他将模型的学习训练分为三个部分:
- 语义估计(Semantic Estimation):使用轻量级的 MobileNetV2 作为骨干网络,提取高层语义
- 细节预测(Detail Prediction):结合了输入图像信息和语义分支的中间特征,对人像边缘进行单独地约束学习
- 语义细节融合(Semantic-Detail Fusion):把语义输出和细节输出结果拼起来后得到最终的 alpha 结果
MODNet 设计的轻量级网络结构大大减少了抠图计算量,降低了抠图模型的使用门槛同时保留了较高的抠图精度,具有较高的实用性。
开发应用实践
尽管 AI 算法研究本身具有一定的门槛,但我们想要开发相应的应用则并不困难,因为网络上有着许多现成的预训练模型,也有现成的 SaaS 服务可供直接使用,在这些已有的能力上去做延伸,我们得以低门槛地创建简单的应用。
部署端对比
虽然使用 AI 技术自动抠图在业界的实际应用已经比较普遍,但是大部分的应用服务都是将模型部署于 GPU 服务器上,基于云 API 对内或对外提供服务。考虑到如果希望在内部场景提供相关的抠图能力,则属于低频功能,单独部署一台服务器将导致其绝大部分时间都处于空置浪费状态。
随着 AI 技术的进步以及用户设备性能的提升,此类 AI 抠图应用已经可以实现在前端内部进行闭环,使用纯前端技术来实现,在较低的性能需求的情况下可以得到相对较好的抠图结果,同时无需额外的 GPU 服务器开销或使用第三方云 API 的费用开销。
| 类别 | 优点 | 缺点 |
|---|---|---|
| 前端 | 前端内部闭环,处理图片时无前后端通信与传输开销;AI 端侧部署是未来主流的发展趋势之一,充分利用性能越来越好的用户设备 | 首次使用需要加载模型文件;性能受限于用户设备,不宜使用过于复杂的大模型 |
| 后台 | 性能无瓶颈,可以使用复杂模型 | 需要有日常的服务器租用开销,服务器性能与费用之间需要进行取舍 |
| 司内/司外现成云 API | 已经提供好基础能力可直接使用 | 受限于第三方,不够灵活,不一定会持续维护更新;司外接口涉及隐私问题;每次使用都会产生费用 |
接下来我们都以前端部署 AI 应用为背景进行讨论。
开源方案
简单搜罗了网络上开源的抠图相关方案,做了一些简单的试用对比,得到对比表格如下:
| 名称 | 优点 | 缺点 | 门槛 | 采用 |
|---|---|---|---|---|
| MODNet | 模型体积小(25.9MB)、推理速度快、效果总体良好、有封装好的预训练模型 | 边缘比较软,会带一点背景色,需要看情况另外优化 | 低 | ✅ |
| RMBG-1.4 | 效果总体良好、边缘清晰,不仅限于人像抠图、有封装好的预训练模型 | 模型体积大(176MB) | 低 | ✅ |
| modern-rembg | 兼容 rembg 的前端版本,支持多种现成预训练模型(u2net、isnet-anime等),可选项多 | 各个模型各有优劣,不够通用 | 中 | ⭕️ |
| tfjs-models/body-segmentation | 模型体积小(20MB以内) | 仅提供了最基础的底层能力,需要自己封装并大量优化,否则效果不佳 | 高 | ⭕️ |
| RobustVideoMatting | (未试用) | 特供于 Web 实时渲染的预训练模型精度很低,需要拿其他的模型进行转换;仅提供了基础底层能力,需要自己封装优化 | 高 | ⭕️ |
| imgly/background-removal-js | 功能完善,开箱即用;不仅限于人像抠图 | 模型体积大,推理速度很慢,抠图效果一般 | 低 | ❌ |
transformers.js 是一个和深度学习相关的 JavaScript 库,基于 onnxruntime-web 的能力在浏览器上运行模型。该库提供了简洁的 API 和丰富的预训练模型,使前端开发者能够轻松地在浏览器中直接使用和运行预训练好的深度学习模型。
综合开发成本以及时间考虑,我们选择使用能够支持 transformers.js 的 MODNet 和 RMBG-1.4 两个抠图模型进行简单的实践。
使用 WebGPU 加速模型推理
我们都知道跑在浏览器的 JS 代码,在性能方面客观上难以和由静态语言编写、直接运行在系统进程里的程序相媲美。特别是在 GPU 的使用上,浏览器在过去通常只能通过 WebGL 实现。因为 WebGL 主要设计用于渲染图形而非通用计算,且性能上受到了硬件以及浏览器的限制,所以并不擅长计算密集型的深度学习任务。
好在,2023 年 5 月份 Chrome 在 113 版本中正式发布了 WebGPU API,使得我们能够在浏览器中使用更简洁易用的 API、更强的计算能力去执行图形和计算任务。
现在(2024 年)WebGPU 还是属于一项实验性技术,只在最新的部分现代浏览器上有支持。但好在 PC 端的现代浏览器都会自动更新到最新版本,所以普及率的问题比移动端要好。

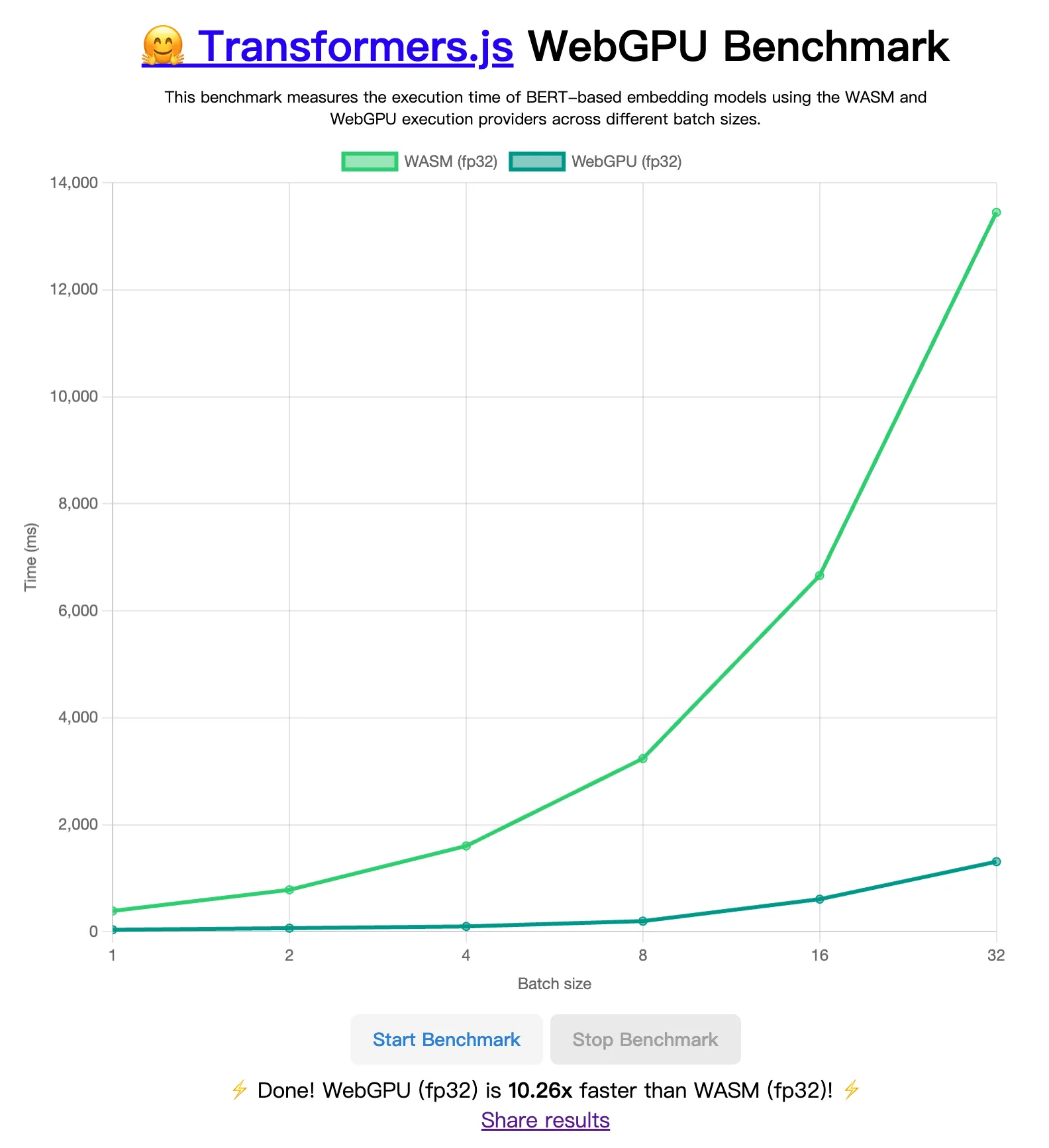
transformers.js 目前也正在适配 WebGPU,预计在 V3 版本中正式发布对 WebGPU 的支持。从这里可以看到 WebGPU 与 WASM 的实时性能对比。下图是用 MacBook Pro Apple M1 Pro 笔记本对于文本嵌入(Text embedding)任务跑出的结果,大概是 10.26x 的性能差距。
transformers.js 的 maintainer 也给出了一个 WebGPU 版本的前端 AI 抠图 Demo,可以从这里访问体验:Xenova/remove-background-webgpu
由于 V3 版本还没有预计正式 release 的时间点,目前想要通过 transformers.js 使用 WebGPU 能力尝鲜的话,需要直接从 github 源安装 v3 分支成依赖使用。(2024.08 更新:作者新增了@huggingface/transformers 包发布预览版,可以直接安装 @huggingface/transformers,不再需要处理从 github 下载依赖的未编译问题)
# npm install xenova/transformers.js#v3
npm install @huggingface/transformers使用时,需要指定 device 为 'webgpu',且 dtype 只支持 'fp32' 和 'fp16'(精度不同)。
import { AutoModel, AutoProcessor } from '@xenova/transformers';
// Load model and processor
const [model, processor] = await Promise.all([
AutoModel.from_pretrained('Xenova/modnet', {
device: 'webgpu',
dtype: 'fp32', // or 'fp16'
}),
AutoProcessor.from_pretrained('Xenova/modnet'),
]);如果需要兼容不支持 WebGPU 的浏览器,可以通过判断
navigator.gpu是否存在进行区分。目前,在 TypeScript 项目中引用navigator.gpu,需要引入@webgpu/types补充类型定义。
抠图 DEMO 实现与效果一览
这里简单写一个抠图 DEMO 获取输入图片的前景图像的 ImageData 对象,就能看出 transformers.js API 在使用上的方便程度:
import { AutoModel, AutoProcessor, RawImage } from '@xenova/transformers';
// Load model and processor
const [model, processor] = await Promise.all([
AutoModel.from_pretrained('Xenova/modnet', {
device: 'webgpu',
dtype: 'fp32',
}),
AutoProcessor.from_pretrained('Xenova/modnet'),
]);
function demo(url: string) {
// Load image from URL
const image = await RawImage.fromURL(url);
// Pre-process image
const { pixel_values } = await processor(image);
// Predict alpha matte
const { output } = await model({ input: pixel_values });
// Get output mask
const mask = await RawImage.fromTensor(output[0].mul(255).to('uint8')).resize(image.width, image.height);
// Composite the original image with the alpha matte
const { width, height, data } = image.rgba();
const imageData = new ImageData(new Uint8ClampedArray(data), width, height);
for (let i = 0; i < width * height; i++) {
const alpha = mask.data[i];
imageData.data[i * 4 + 3] = alpha;
}
return imageData;
}分别使用 MODNet 和 RMBG-1.4 两个模型进行测试,得到的输出结果对比如下:
| 输入图像(1024x683) | MODNet 抠图结果(耗时 295ms) | RMBG-1.4 抠图结果(645ms) |
|---|---|---|
 |  |  |
| 输入图像(1098x1098) | MODNet 抠图结果(耗时 327ms) | RMBG-1.4 抠图结果(652ms) |
|---|---|---|
 |  |  |
抠图结果放在透明白色底背景对比不明显,需要放在深色背景下对比
注意模型推理的耗时状况,可见在 WebGPU 的加持下,在 Web 端侧运行 AI 抠图模型是完全可行的。
与业务相结合
业务背景
在我司的道具打赏业务中,展示打赏爆灯特效需要使用到从媒资库拉取的明星头像图片,而从媒资库拉取的明星头像通常带有相对复杂的人物背景,不一定有纯人物的透明背景人像素材,不适合直接用于爆灯特效场景。
以往的常规做法是:由运营同学再找设计同学协助,针对这些非透明背景的明星头像重新抠图,使用新图干预配置结果,这导致设计和运营同学的工作量大大增加。尤其在跨年直播、星光大赏这种明星人数非常多的情况下,手动抠图并配置的工作量大、流程繁琐,出错的概率较高。
另外,手动抠图的质量也不总是十分完美的。如果为了追求效率或者要求标准不高,手动抠图的质量也会参差不齐。
所以我们希望应用 AI 技术实现人像一键抠图去除背景,减轻设计工作量,提升运营配置效率。在将这些技术应用到具体业务的过程中,我们也能与现有业务进行有机的结合,以更直接和贴切的方式解决业务的实际痛点。
项目设计
为了后续能够将同一套抠图能力尽可能简单地复用到多个场景的业务中去,我们将核心的抠图能力封装为一个基础 SDK,隐藏不同模型在使用上的差异,对外提供简易的 API:
// Create remover
const remover = createBackgroundRemoval('rmbg'); // or 'modnet'
// Model initialization load
await remover.load();
// Execute matting task
const result = await remover.run({
input: image,
output: {
type: 'data-url',
},
} satisfies RemovalOptions); // result is base64 image data URL
// Options definition
interface RemovalOptions {
input: HTMLImageElement | ImageData | RawImage | Blob | URL | DataURL | string;
output?: {
type?: 'blob' | 'data-url' | 'image-data';
};
}为了实现更多拓展性的功能,我们在此基础 SDK 上,二次封装了一个带有弹窗 UI 组件的 SDK,提供通用的交互界面与常用的调整项,支持抠图结果预览、切换模型、微调参数、批量抠图等功能。
设计稿初稿参考:
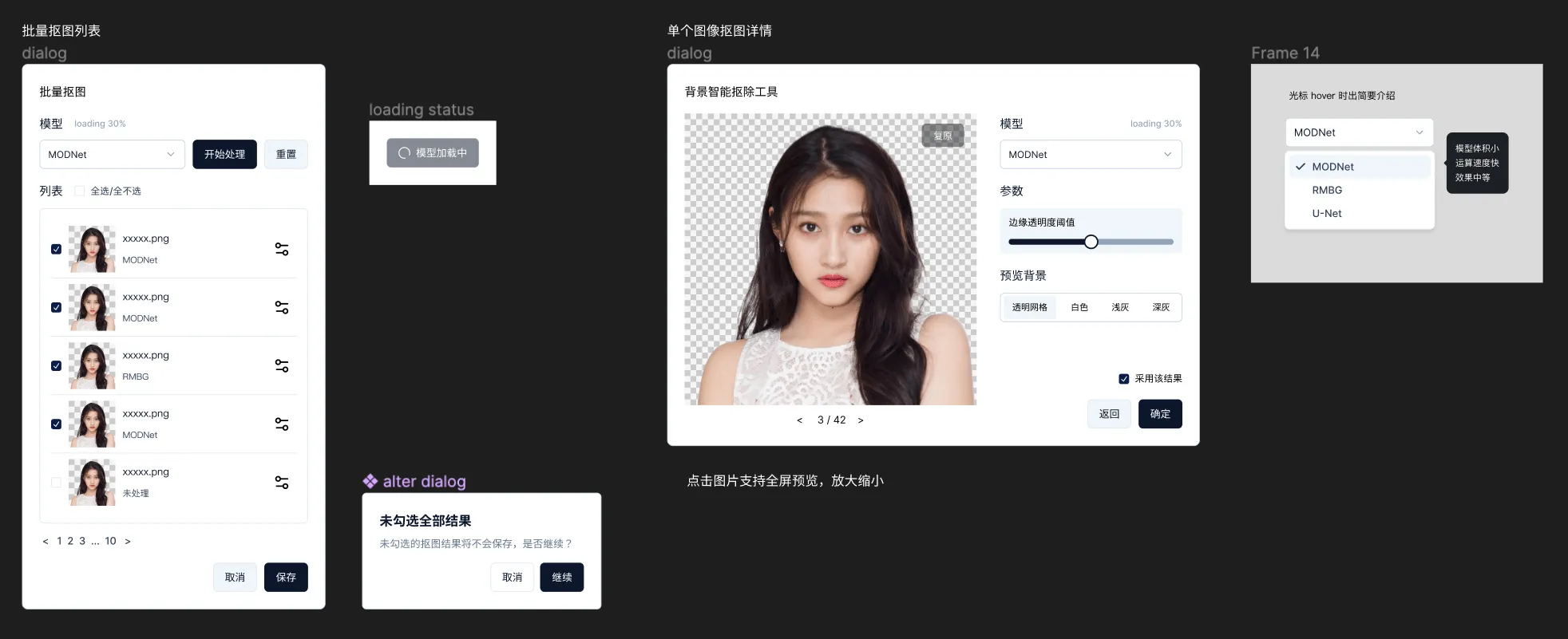
使用示例:
removeBackground({
input: pic, // pic 支持数组类型或者单个元素传入
onConfirm: (value) => {
console.debug('onConfirm', value); // 当 pic 为数组时,value也为数组;反之亦然
},
});参数的类型定义:
type ImageSource = HTMLImageElement | ImageData | RawImage | Blob | URL | DataURL | string;
interface PopupParams {
/** 输入图像 */
input?: ImageSource | ImageSource[];
/** 输出图像的配置 */
output?: {
/** 输出图像类型 */
type?: 'blob' | 'data-url' | 'image-data';
};
/** 抠图模型类型(默认 rmbg) */
model?: 'rmbg' | 'modnet';
/** 额外功能选项 */
options?: {
/** 上传图片的数量限制(不启用上传/单张/多张) */
uploadType?: 'disabled' | 'single' | 'multiple';
/** 是否支持用户手动选择抠图模型 */
modelSelectable?: boolean;
};
/** 抠图完毕返回结果时回调 */
onConfirm: (value: ResultType | ResultType[]) => void; // ResultType 取决于 output.type
/** 失败回调 */
onError?: (error: unknown) => void;
/** 取消抠图关闭弹窗时的回调 */
onCancel?: () => void;
/** 弹窗关闭时的回调 */
onClose?: () => void;
}更多延伸
除了 transformers.js 的方案以外,还有许多其他的抠图模型与方案也都值得一试。往往不同的场景、不同的限制条件下,不同的模型能够取得更好的效果。
如果要准确的评价算法模型的抠图效果,还可以在网络上下载一些抠图数据集(例如 PPM-100),以量化的标准(均方误差 MSE、平均差 MAD 等)衡量模型的表现。